4.2 x64dbg 针对PE文件的扫描
通过运用LyScript插件并配合pefile模块,即可实现对特定PE文件的扫描功能,例如载入PE程序到内存,验证PE启用的保护方式,计算PE节区内存特征,文件FOA与内存VA转换等功能的实现,首先简单介绍一下pefile模块。
pefile模块是一个用于解析Windows可执行文件(PE文件)的Python模块,它可以从PE文件中提取出文件头、节表、导入表、导出表、资源表等信息,也可以修改PE文件的一些属性。可以用于分析针对Windows平台的恶意软件、编写自己的PE文件修改工具等场景。
使用pefile模块可以快速方便地定位到PE文件的一些关键信息,例如程序入口点、程序头、代码的开始和结束位置等,在基于PE文件进行逆向分析和开发中非常有用。在Python中使用pefile模块也非常简单,通过导入模块和加载PE文件后就可以轻松获取和修改PE文件的各种属性了。
4.2.1 获取PE结构内存节表
在读者使用LyScript扫描进程PE结构之前,请读者自行执行pip install pefile将pefile模块安装到系统中,接着我们开始实现第一个功能,将PE可执行文件中的内存数据通过PEfile模块打开并读入内存,实现PE参数解析。
此功能的核心实现原理,通过get_local_base()得到text节的基址,然后再通过get_base_from_address()函数得到text节得到程序的首地址,通过read_memory_byte依次读入数据到内存中,最后使用pefile.PE解析为PE结构,其功能如下所示:
- 1.使用
MyDebug模块创建并初始化dbg对象,连接调试环境。 - 2.调用
dbg.get_local_base()获取调试程序的基地址,将其赋值给local_base变量。 - 3.调用
dbg.get_base_from_address(local_base)将调试器地址转换为程序入口地址,将转换后的地址赋值给base变量。 - 4.使用循环遍历方式读取调试程序首地址处的
4096字节数据并存储到byte_array字节数组中。 - 5.使用
pefile模块创建一个PE文件对象oPE,并将byte_array作为数据源传入。 - 6.最后使用
dump_dict()方法从PE文件对象中提取出可选头信息并打印输出timedate变量。
具体的实现细节可以总结为如下代码形式;
from LyScript32 import MyDebug
import pefile
if __name__ == "__main__":
# 初始化
dbg = MyDebug()
dbg.connect()
# 得到text节基地址
local_base = dbg.get_local_base()
# 根据text节得到程序首地址
base = dbg.get_base_from_address(local_base)
byte_array = bytearray()
for index in range(0,4096):
read_byte = dbg.read_memory_byte(base + index)
byte_array.append(read_byte)
oPE = pefile.PE(data = byte_array)
timedate = oPE.OPTIONAL_HEADER.dump_dict()
print(timedate)
保存并运行这段代码,读者可以看到如下所示的输出效果;

总体上,这段代码的作用是利用调试器将调试程序的首地址处的4096字节读入内存,然后使用pefile模块将其解析为PE文件,最后输出PE文件的可选头信息。该代码可以用于在调试过程中对调试程序的PE文件进行逆向分析和研究。
接着我们继续向下解析,通常读者可通过oPE.sections获取到当前进程的完整节数据,如下通过LyScirpt模块配合PEFile模块解析内存镜像中的section节表属性,其完整代码如下所示;
from LyScript32 import MyDebug
import pefile
if __name__ == "__main__":
# 初始化
dbg = MyDebug()
dbg.connect()
# 得到text节基地址
local_base = dbg.get_local_base()
# 根据text节得到程序首地址
base = dbg.get_base_from_address(local_base)
byte_array = bytearray()
for index in range(0,8192):
read_byte = dbg.read_memory_byte(base + index)
byte_array.append(read_byte)
oPE = pefile.PE(data = byte_array)
for section in oPE.sections:
print("%10s %10x %10x %10x"
%(section.Name.decode("utf-8"), section.VirtualAddress,
section.Misc_VirtualSize, section.SizeOfRawData))
dbg.close()
读者可自行运行这段代码片段,则会看到当前被加载进程中内存节表的完整输出,这段代码输出效果如下图所示;
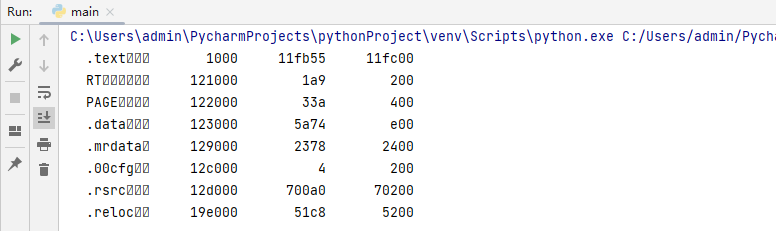
4.2.2 计算节表内存Hash散列值
接着我们继续再进一步,实现计算PE节表Hash散列值,Hash函数的计算常用于病毒木马特征值的标记,通过对特定文件进行散列值生成,即可得知该文件的版本,从而实现快速锁定源文件的目的。
什么是Hash散列值
哈希散列值通常被用作数字签名、数据完整性验证、消息认证等等领域,它可以根据数据的内容计算出一个固定长度的值(通常是16到64字节),并且在数据被篡改的情况下会生成不同的散列值,因此可以用来在不传输原数据的情况下验证数据的完整性。
例如,我们可以使用MD5哈希函数对一个文件进行哈希计算,得到一个128位的哈希散列值,将其与原始文件共同存储在另一个不同的地方。当我们需要验证此文件是否被篡改时,只需要重新对文件进行哈希计算,得到一个新的散列值,并将其与原来存储的散列值进行比对,如果两个值相同,就可以确定文件未被篡改。
什么是Hash散列函数
哈希散列函数,也叫哈希函数,是一种将任意长度的消息映射到固定长度的散列值的函数。它通常是通过执行一系列算法将输入数据转换为一个固定大小的二进制数据而实现的。
哈希散列函数是密码学中的重要工具之一,它具有不可逆性、单向性(难以从散列值反推源数据)、抗碰撞性(不同的源数据计算出来的散列值相等的概率很小)等特性,广泛应用于数据加密、身份认证、数字签名等领域。
常见的哈希散列函数有MD5、SHA-1、SHA-2、SHA-3等,其中SHA-2是应用最广泛的哈希函数之一,在许多加密协议和安全标准中被广泛使用。虽然哈希函数具有不可逆性,但是由于计算能力的不断提高,一些强大的计算能力可以被用来破解哈希函数,因此选择合适的哈希函数也非常重要。
我们以MD5以及CRC32为例,如果读者需要计算程序中每个节的散列值,则需通过dbg.get_section()函数动态获取到所有程序中的节,并取出addr,name,size三个字段,通过封装的md5()以及crc32等函数完成计算并输出,这段代码的核心实现流程如下所示;
import binascii
import hashlib
from LyScript32 import MyDebug
def crc32(data):
return "0x{:X}".format(binascii.crc32(data) & 0xffffffff)
def md5(data):
md5 = hashlib.md5(data)
return md5.hexdigest()
if __name__ == "__main__":
dbg = MyDebug()
dbg.connect()
# 循环节
section = dbg.get_section()
for index in section:
# 定义字节数组
mem_byte = bytearray()
address = index.get("addr")
section_name = index.get("name")
section_size = index.get("size")
# 读出节内的所有数据
for item in range(0,int(section_size)):
mem_byte.append( dbg.read_memory_byte(address + item))
# 开始计算特征码
md5_sum = md5(mem_byte)
crc32_sum = crc32(mem_byte)
print("[*] 节名: {:10s} | 节长度: {:10d} | MD5特征: {} | CRC32特征: {}"
.format(section_name,section_size,md5_sum,crc32_sum))
dbg.close()
运行后等待片刻,读者应该可以看到如下图所示的输出结果,图中每一个节的散列值都被计算出来;

4.2.3 验证PE启用的保护模式
PE文件的保护模式包括了、随机基址(Address space layout randomization,ASLR)、数据不可执行(Data Execution Prevention,DEP)、强制完整性(Forced Integrity,FCI)这四种安全保护机制,它们的主要作用是防止恶意软件攻击,并提高系统的安全性和可靠性。
1.随机基址(Address space layout randomization,ASLR)
随机基址是一种Windows操作系统中的内存防护机制,它可以使恶意软件难以通过内存地址预测来攻击应用程序。在随机基址机制下,操作系统会随机改变应用程序的地址空间布局,使得每次运行时程序在内存中加载的地址不同,从而防止攻击者凭借对程序内存地址的猜测或破解来攻击程序。
随机基址的验证方式是定位到PE结构的pe.OPTIONAL_HEADER.DllCharacteristics并对PE文件的OPTIONAL_HEADER中的DllCharacteristics属性进行取值位运算操作并以此作为判断的依据:
- 首先,使用
hex()将pe.OPTIONAL_HEADER.DllCharacteristics转换为16进制字符串。 - 然后,将该16进制字符串和
0x40进行按位与运算。 - 最后,将得到的结果与
0x40进行比较。
根据微软的文档,pe.OPTIONAL_HEADER.DllCharacteristics是一个32位的掩码属性,用于描述PE文件的一些特性。其中DllCharacteristics的第7位(从0开始)表示该文件是否启用了ASLR(Address Space Layout Randomization)特性,如果启用,则对应值为0x40。因此,上述代码的作用是判断该PE文件是否启用了ASLR特性。如果结果为真,则说明该文件启用了ASLR;否则,说明该文件未启用ASLR。
数据不可执行(Data Execution Prevention,DEP)
数据不可执行是一种Windows操作系统中的内存防护机制,它可以防止恶意软件针对系统内存中的数据进行攻击。在DEP机制下,操作系统会将内存分为可执行和不可执行两部分,其中不可执行部分主要用于存放程序数据,而可执行部分用于存放代码。这样当程序试图执行不可执行的数据时,操作系统会立即终止程序,从而防止攻击者通过操纵程序数据来攻击系统。
同样使用位运算符&,对PE文件的OPTIONAL_HEADER中的DllCharacteristics属性进行了取值并进行了位运算操作。该代码的具体意义为:
- 首先,使用hex()将
pe.OPTIONAL_HEADER.DllCharacteristics转换为16进制字符串。 - 然后,将该16进制字符串和
0x100进行按位与运算。 - 最后,将得到的结果与
0x100进行比较。
根据微软的文档,pe.OPTIONAL_HEADER.DllCharacteristics是一个32位的掩码属性,用于描述PE文件的一些特性。其中,DllCharacteristics的第8位(从0开始)表示该文件是否启用了NX特性(No eXecute),如果启用,则对应值为0x100。NX特性是一种内存保护机制,可以防止恶意代码通过将数据区域当作代码区域来执行代码,提高了系统的安全性。因此,上述代码的作用是判断该PE文件是否启用了NX特性。如果结果为真,则说明该文件启用了NX特性;否则,说明该文件未启用NX特性。
强制完整性(Forced Integrity,FCI)
强制完整性是一种Windows操作系统中的强制措施,它可以防止恶意软件通过DLL注入来攻击系统。在FCI机制下,操作系统会通过数字签名和其他校验措施对系统DLL和其他关键文件进行验证,确保这些文件没有被修改或替换。如果检测到文件已被修改或替换,操作系统将会拒绝这些文件并终止相关进程,这样可以保护系统的完整性和安全性。
同样使用位运算符&,对PE文件的OPTIONAL_HEADER中的DllCharacteristics属性进行了取值并进行了位运算操作。该代码的具体意义为:
- 首先,使用hex()将
pe.OPTIONAL_HEADER.DllCharacteristics转换为16进制字符串。 - 然后,将该16进制字符串和0x80进行按位与运算。
- 最后,将得到的结果与0x80进行比较。
根据微软的文档,pe.OPTIONAL_HEADER.DllCharacteristics是一个32位的掩码属性,用于描述PE文件的一些特性。其中,DllCharacteristics的第7位(从0开始)表示该文件是否启用了动态基址特性(Dynamic Base),如果启用,则对应值为0x40。动态基址特性与ASLR(Address Space Layout Randomization)功能是紧密相关的,当启用ASLR时,动态基址特性也会被自动启用。因此,上述代码的作用是判断该PE文件是否启用了动态基址特性。如果结果为真,则说明该文件启用了动态基址特性;否则,说明该文件未启用动态基址特性。
根据如上描述,要想实现检查进程内所有模块的保护方式,则首先要通过dbg.get_all_module()获取到进程的所有模块信息,当模块信息被读入后,通过dbg.read_memory_byte()获取到该内存的机器码,并通过pefile.PE(data=byte_array)装载到内存,通过对不同数值与与运算即可判定是否开启了保护。
- 随机基址 hex(pe.OPTIONAL_HEADER.DllCharacteristics) & 0x40 == 0x40
- 数据不可执行 hex(pe.OPTIONAL_HEADER.DllCharacteristics) & 0x100 == 0x100
- 强制完整性 hex(pe.OPTIONAL_HEADER.DllCharacteristics) & 0x80 == 0x80
那么根据如上描述,这段核心代码可以总结为如下案例;
from LyScript32 import MyDebug
import pefile
if __name__ == "__main__":
# 初始化
dbg = MyDebug()
dbg.connect()
# 得到所有加载过的模块
module_list = dbg.get_all_module()
print("-" * 100)
print("模块名 \t\t\t 基址随机化 \t\t DEP保护 \t\t 强制完整性 \t\t SEH异常保护 \t\t")
print("-" * 100)
for module_index in module_list:
print("{:15}\t\t".format(module_index.get("name")),end="")
# 依次读入程序所载入的模块
byte_array = bytearray()
for index in range(0, 4096):
read_byte = dbg.read_memory_byte(module_index.get("base") + index)
byte_array.append(read_byte)
oPE = pefile.PE(data=byte_array)
# 随机基址 => hex(pe.OPTIONAL_HEADER.DllCharacteristics) & 0x40 == 0x40
if ((oPE.OPTIONAL_HEADER.DllCharacteristics & 64) == 64):
print("True\t\t\t",end="")
else:
print("False\t\t\t",end="")
# 数据不可执行 DEP => hex(pe.OPTIONAL_HEADER.DllCharacteristics) & 0x100 == 0x100
if ((oPE.OPTIONAL_HEADER.DllCharacteristics & 256) == 256):
print("True\t\t\t",end="")
else:
print("False\t\t\t",end="")
# 强制完整性=> hex(pe.OPTIONAL_HEADER.DllCharacteristics) & 0x80 == 0x80
if ((oPE.OPTIONAL_HEADER.DllCharacteristics & 128) == 128):
print("True\t\t\t",end="")
else:
print("False\t\t\t",end="")
if ((oPE.OPTIONAL_HEADER.DllCharacteristics & 1024) == 1024):
print("True\t\t\t",end="")
else:
print("False\t\t\t",end="")
print()
dbg.close()
读者可以运行这段案例,即可看到如下图所示的输出效果;
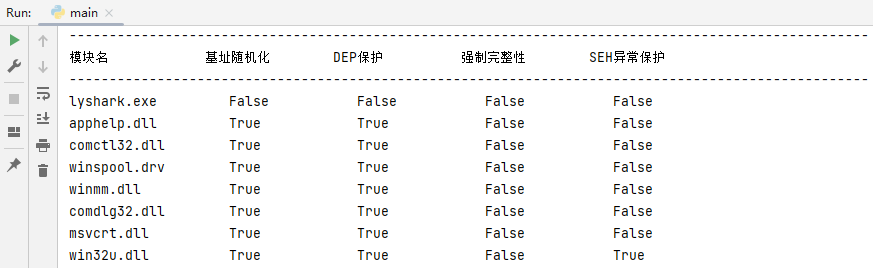
4.2.4 PE结构的FOA/VA/RAV转换
在PE文件结构中,VA、RVA和FOA都是用来描述内存中数据的位置和在文件中的偏移量,具体含义如下:
- VA(Virtual Address):虚拟地址,也叫映像地址,是指在内存中的地址。VA通常是程序运行时要访问的地址,由操作系统进行地址转换映射到物理地址上。
- RVA(Relative Virtual Address):相对虚拟地址,是指当前位置相对于所在塞段的起始地址的偏移量。RVA通常是用于描述PE文件中的各个段的相对位置,它不像VA一样是用于真正运行程序的,而是在加载 PE 文件时进行重定位所使用的。
- FOA(File Offset Address):文件偏移量,是指在文件中的偏移量,也就是从文件起始位置到数据的偏移量。FOA通常是用于描述PE文件中的各个段和头信息在文件中的位置,可以用来定位和修改文件中的数据。
需要注意的是,这三种地址是不同的,其值也不同。VA和RVA通常是在Windows操作系统中使用;FOA通常是在PE文件处理时使用。在PE文件加载时,Windows操作系统会将RVA转换为VA,将程序的段加载到内存中,并根据需要对其进行重定位(如果代码中包含有绝对地址的话),然后将控制权交给程序的入口点,程序进入执行状态。
首先实现VA转为FOA的案例,在这段核心代码中,通过dbg.get_base_from_address(dbg.get_local_base())获取到内存中的程序基地址,并与VA地址相减得到内存中的RVA地址,并调用PEfile库中的get_offset_from_rva完成转换。
def get_offset_from_va(pe_ptr, va_address):
# 得到内存中的程序基地址
memory_image_base = dbg.get_base_from_address(dbg.get_local_base())
# 与VA地址相减得到内存中的RVA地址
memory_local_rva = va_address - memory_image_base
# 根据RVA得到文件内的FOA偏移地址
foa = pe_ptr.get_offset_from_rva(memory_local_rva)
return foa
其次是将FOA文件偏移转为VA虚拟地址,此类代码与上方代码基本一致,通过pe_ptr.get_rva_from_offset先得到RVA相对偏移,然后在通过dbg.get_base_from_address(dbg.get_local_base())得到内存中程序基地址,然后计算VA地址,最后直接计算得到VA地址。
def get_va_from_foa(pe_ptr, foa_address):
# 先得到RVA相对偏移
rva = pe_ptr.get_rva_from_offset(foa_address)
# 得到内存中程序基地址,然后计算VA地址
memory_image_base = dbg.get_base_from_address(dbg.get_local_base())
va = memory_image_base + rva
return va
最后一种则是将FOA文件偏移地址转为RVA相对地址,此类代码中通过枚举所有节中的参数,并以此动态计算出实际的RVA地址返回。
# 传入一个FOA文件地址转为RVA地址
def get_rva_from_foa(pe_ptr, foa_address):
sections = [s for s in pe_ptr.sections if s.contains_offset(foa_address)]
if sections:
section = sections[0]
return (foa_address - section.PointerToRawData) + section.VirtualAddress
else:
return 0
最终将三段代码整合在一起,即可构成一个互相转换的案例,至于PE结构的解析问题,详细度过PE结构篇的你不需要我做太多的解释了。
from LyScript32 import MyDebug
import pefile
# 传入一个VA值获取到FOA文件地址
def get_offset_from_va(pe_ptr, va_address):
# 得到内存中的程序基地址
memory_image_base = dbg.get_base_from_address(dbg.get_local_base())
# 与VA地址相减得到内存中的RVA地址
memory_local_rva = va_address - memory_image_base
# 根据RVA得到文件内的FOA偏移地址
foa = pe_ptr.get_offset_from_rva(memory_local_rva)
return foa
# 传入一个FOA文件地址得到VA虚拟地址
def get_va_from_foa(pe_ptr, foa_address):
# 先得到RVA相对偏移
rva = pe_ptr.get_rva_from_offset(foa_address)
# 得到内存中程序基地址,然后计算VA地址
memory_image_base = dbg.get_base_from_address(dbg.get_local_base())
va = memory_image_base + rva
return va
# 传入一个FOA文件地址转为RVA地址
def get_rva_from_foa(pe_ptr, foa_address):
sections = [s for s in pe_ptr.sections if s.contains_offset(foa_address)]
if sections:
section = sections[0]
return (foa_address - section.PointerToRawData) + section.VirtualAddress
else:
return 0
if __name__ == "__main__":
dbg = MyDebug()
dbg.connect()
# 载入文件PE
pe = pefile.PE(name=dbg.get_local_module_path())
# 读取文件中的地址
rva = pe.OPTIONAL_HEADER.AddressOfEntryPoint
va = pe.OPTIONAL_HEADER.ImageBase + pe.OPTIONAL_HEADER.AddressOfEntryPoint
foa = pe.get_offset_from_rva(pe.OPTIONAL_HEADER.AddressOfEntryPoint)
print("文件VA地址: {} 文件FOA地址: {} 从文件获取RVA地址: {}".format(hex(va), foa, hex(rva)))
# 将VA虚拟地址转为FOA文件偏移
eip = dbg.get_register("eip")
foa = get_offset_from_va(pe, eip)
print("虚拟地址: 0x{:x} 对应文件偏移: {}".format(eip, foa))
# 将FOA文件偏移转为VA虚拟地址
va = get_va_from_foa(pe, foa)
print("文件地址: {} 对应虚拟地址: 0x{:x}".format(foa, va))
# 将FOA文件偏移地址转为RVA相对地址
rva = get_rva_from_foa(pe, foa)
print("文件地址: {} 对应的RVA相对地址: 0x{:x}".format(foa, rva))
dbg.close()
如上代码中所传递地址必须保证是正确的,否则会报错,读者应根据自己的需求选择对应的函数来执行,代码运行后输出效果如下图所示;

4.2.5 PE结构检索SafeSEH内存地址
SafeSEH(Safe Structured Exception Handling)是Windows操作系统提供的一种安全保护机制,用于防止恶意软件利用缓冲区溢出漏洞来攻击应用程序。
当应用程序使用结构化异常处理机制(SEH)时,其异常处理链表(ExceptionHandler链表)可以被攻击者用来执行代码注入攻击。这是由于异常处理链表本质上是一个指针数组,如果应用程序使用了未经验证的指针指向异常处理函数,则攻击者可以构造恶意的异常处理模块来覆盖原有的处理程序,从而迫使程序执行攻击者注入的代码。这种攻击技术被称为SEH注入(SEH Overwrite)。
为了解决这个问题,SafeSEH机制被引入到Windows操作系统中。其主要思想是在应用程序的导入表中加入了一个SafeSEH表,用于存储由编译器生成的SEH处理函数的地址列表。在程序执行时,Windows操作系统将检查程序SEH链表中的指针是否存在SafeSEH表中。如果该指针不存在于SafeSEH表中,则Windows操作系统将终止应用程序的执行。SafeSEH机制可以提高系统的安全性和可靠性,防止恶意软件利用缓冲区溢出和SEH注入等漏洞来攻击应用程序。
SafeSEH的检索问题,读者可依据如下步骤依次实现;
- 1.初始化调试器dbg,并执行dbg.connect()连接到正在运行的进程。
- 2.memory_image_base = dbg.get_base_from_address(dbg.get_local_base()):获取程序内存镜像的基地址。
- 3.peoffset = dbg.read_memory_dword(memory_image_base + int(0x3c)):通过PE头的偏移地址得到PE头的基地址。
- 4.flags = dbg.read_memory_word(pebase + int(0x5e)):读取PE头中的DllCharacteristics属性的值,使用了read_memory_word函数,该值用于判断是否开启了SafeSEH保护。
- 5.如果flags值的第10位(即0x400)为1,则说明该程序已开启了SafeSEH保护,并输出保护状态为“NoHandler”;否则不打印状态信息。
- 6.numberofentries = dbg.read_memory_dword(pebase + int(0x74)):读取PE头中的NumberOfRvaAndSizes属性的值,该值用来描述数据目录表中的项目个数。
- 7.如果numberofentries值大于10,则说明该PE文件结构异常,退出程序。
- 8.sectionaddress和sectionsize用于指定程序头表中第10个PE节的地址和大小。如果第10个节大小不为0且为0x40或与第一个DWORD和第二个DWORD的值相等,则说明该程序在节表中找到了SafeSEH记录。
- 9.sehlistaddress和sehlistsize指定
SafeSEH记录列表的地址和大小。如果sehlistaddress不为0且sehlistsize不为0,则说明该程序启用了SafeSEH保护,并输出保护状态。 - 10.如果condition等于False,则说明PE结构不符合要求或未启用SafeSEH保护。如果data小于0x48,则说明该DLL或EXE程序无法被识别。如果sehlistaddress和sehlistsize不同时等于零,则打印SafeSEH保护中的长度。
查找SafeSEH内存地址,读入PE文件到内存,验证该程序的SEH保护是否开启,如果开启则尝试输出SEH内存地址,其实现代码可总结为如下案例;
from LyScript32 import MyDebug
import struct
LOG_HANDLERS = True
if __name__ == "__main__":
dbg = MyDebug()
dbg.connect()
# 得到PE头部基地址
memory_image_base = dbg.get_base_from_address(dbg.get_local_base())
peoffset = dbg.read_memory_dword(memory_image_base + int(0x3c))
pebase = memory_image_base + peoffset
flags = dbg.read_memory_word(pebase + int(0x5e))
if(flags & int(0x400)) != 0:
print("SafeSEH | NoHandler")
numberofentries = dbg.read_memory_dword(pebase + int(0x74))
if numberofentries > 10:
# 读取 pebase+int(0x78)+8*10 | pebase+int(0x78)+8*10+4 读取八字节,分成两部分读取
sectionaddress, sectionsize = [dbg.read_memory_dword(pebase+int(0x78)+8*10),
dbg.read_memory_dword(pebase+int(0x78)+8*10 + 4)
]
sectionaddress += memory_image_base
data = dbg.read_memory_dword(sectionaddress)
condition = (sectionsize != 0) and ((sectionsize == int(0x40)) or (sectionsize == data))
if condition == False:
print("[-] SafeSEH 无保护")
if data < int(0x48):
print("[-] 无法识别的DLL/EXE程序")
sehlistaddress, sehlistsize = [dbg.read_memory_dword(sectionaddress+int(0x40)),
dbg.read_memory_dword(sectionaddress+int(0x40) + 4)
]
if sehlistaddress != 0 and sehlistsize != 0:
print("[+] SafeSEH 保护中 | 长度: {}".format(sehlistsize))
if LOG_HANDLERS == True:
for i in range(sehlistsize):
sehaddress = dbg.read_memory_dword(sehlistaddress + 4 * i)
sehaddress += memory_image_base
print("SEHAddress = {}".format(hex(sehaddress)))
dbg.close()
运行这段代码,则可输出当前进程内所有启用SafeSEH的内存地址空间,如下图所示;
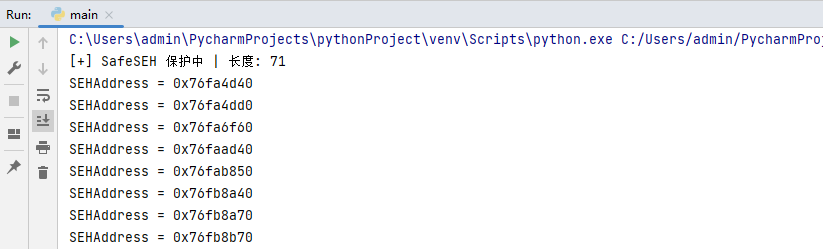
原文地址
https://www.lyshark.com/post/558b1012.html
文章出处:https://www.cnblogs.com/LyShark/p/17533827.html
本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!