网络问题排查必备利器:Pingmesh
背景
当今的数字化世界离不开无处不在的网络连接。无论是日常生活中的社交媒体、电子商务,还是企业级应用程序和云服务,我们对网络的依赖程度越来越高。然而,网络的可靠性和性能往往是一个复杂的问题,尤其是在具有大规模分布式架构的系统中。
在过去,网络监控主要依赖于传统的点对点(point-to-point)方式,通过单独的监控工具对网络路径进行测试。然而,这种方法往往只能提供有限的信息,并且无法全面评估整个网络的健康状况。为了更好地了解网络的运行情况以及及时发现潜在的问题,Pingmesh 技术应运而生。
Pingmesh 的提出最初是来自微软,在微软内部 Pingmesh 每天会记录 24TB 数据,进行 2000 亿次 ping 探测,通过这些数据,微软可以很好的进行网络故障判定和及时的修复。
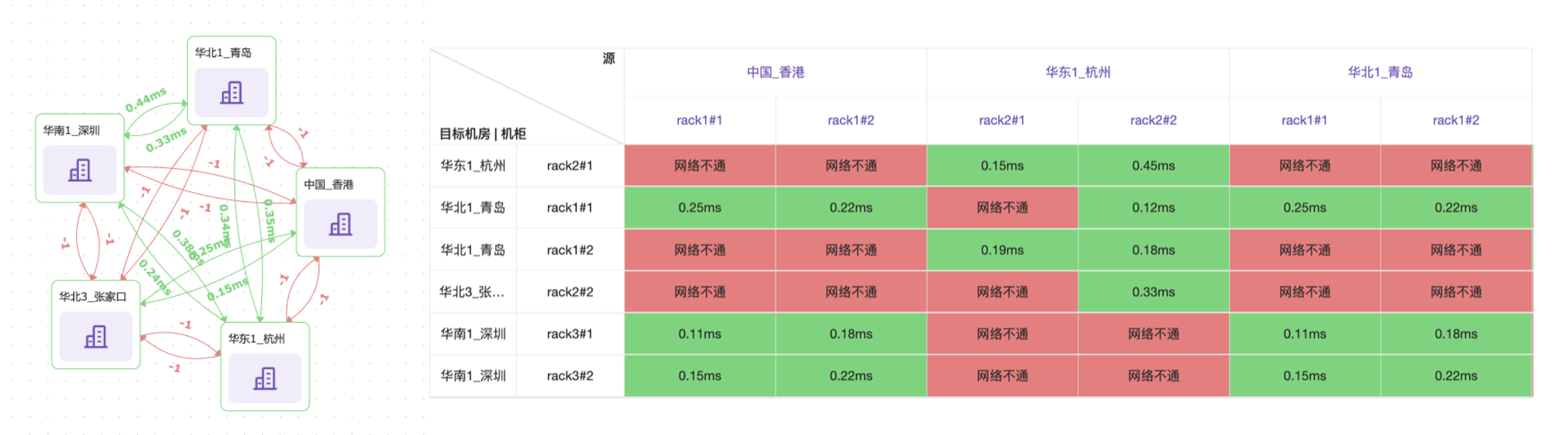
下面是 Flashcat Pingmesh 的页面样例,可以清晰地看到各个机房之间的网络情况,也可以看到各个机柜或交换机之间的情况:
业界方案
业界对Pingmesh的实现大都基于微软的一则论文为基础,做出了一些改造和升级。原微软Pingmesh论文地址: 《Pingmesh: A Large-Scale System for Data Center Network Latency Measurement and Analysis》。
常见的数据中心网络拓扑:
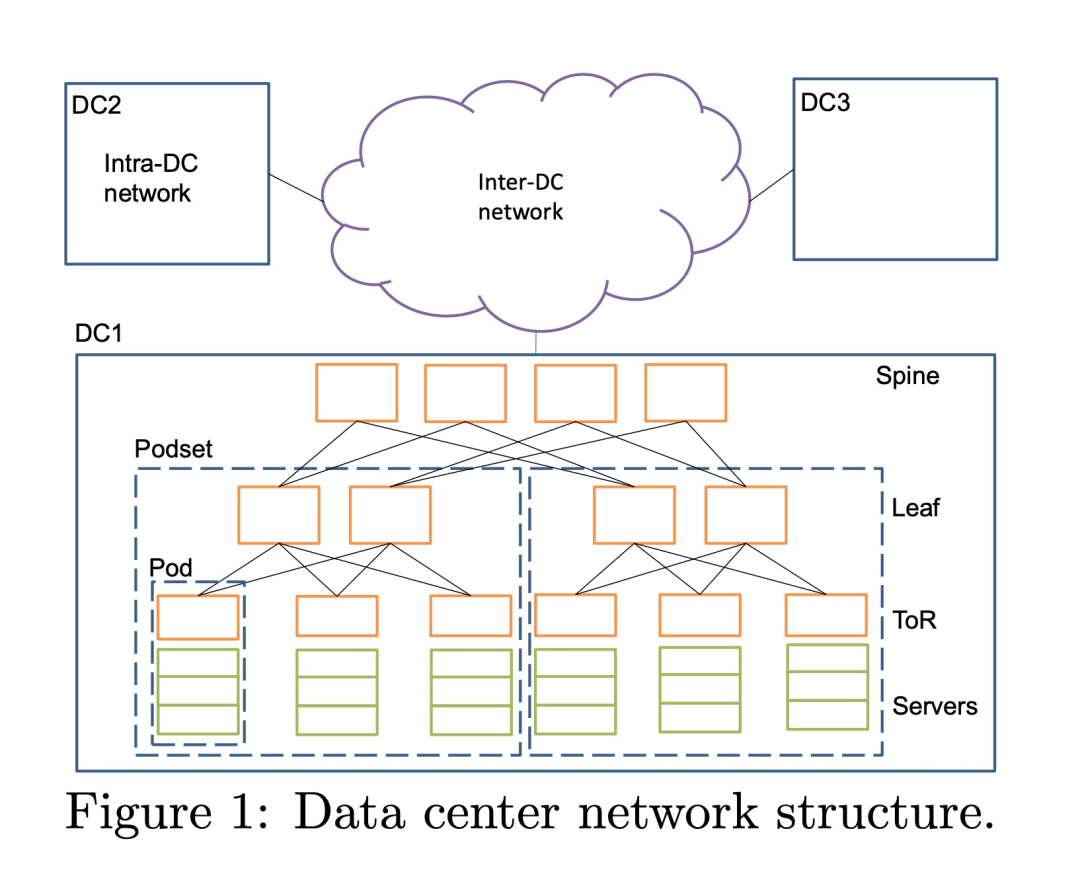
在这样的架构中,有多个数据中心,数据中心之间有专线连通,在数据中心内部有多个Spine、Leaf、ToR交换机,在一些架构中,leaf交换机也会直接充当ToR作为服务器接入交换机,在 ToR 交换机下有大量服务器连接; 因此,pingmesh 能力就分为3 个级别:
- 在机架内部,让所有的 server 互相 ping,每个 server ping 机架内其他 N-1 个 server
- 在机架之间,则每个机架选几个 server ping 其他机架的 server,保证 server 所属的 ToR 不同
- 在数据中心之间,则选择不同的数据中心的几个不同机架的 server 来ping
Pingmesh 架构设计
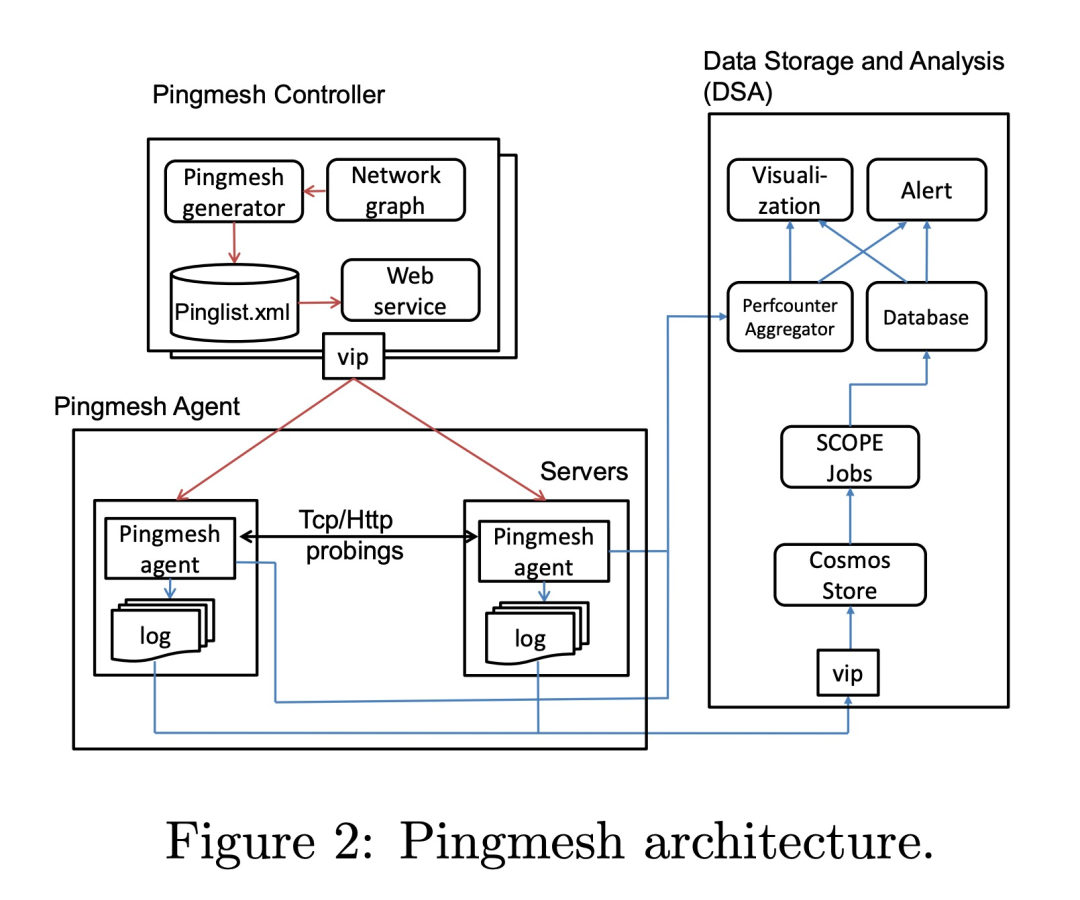
Controller
Controller 主要负责生成 pinglist 文件,这个文件是 XML 格式的,pinglist 的生成是很重要的,需要根据实际的数据中心网络拓扑进行及时更新。 在生成 pinglist 时, Controller 为了避免开销,分为3 个级别:
- 在机架内部,让所有的 server 互相 ping,每个 server ping (N-1) 个 server
- 在机架之间,则每个机架选几个 server ping 其他机架的 server,保证 server 所属的 ToR 不同
- 在数据中心之间,则选择不同的数据中心的几个不同机架的 server 来ping
Controller 在生成 pinglist 文件后,通过 HTTP 提供出去,Agent 会定期获取 pinglist 来更新 agent 自己的配置,也就是我们说的“拉”模式。Controller 需要保证高可用,因此需要在 VIP 后面配置多个实例,每个实例的算法一致,pinglist 文件内容也一致,保证可用性。
Agent
微软数据中心的每个 server 都会运行 Agent,用来真正做 ping 动作的服务。为了保证获取结果与真实的服务一致,Pingmesh 没有采用 ICMP ping,而是采用的 TCP/HTTP ping。所以每个 Agent 既是 Server 也是 Client。每个 ping 动作都开启一个新的连接,主要为了减少 Pingmesh 造成的 TCP 并发。 Agent 要保证自己是可靠的,不会造成一些严重的后果,其次要保证自己使用的资源要足够的少,毕竟要运行在每个 server 上。两个server ping 的周期最小是 10s,Packet 大小最大 64kb。针对灵活配置的需求,Agent 会定期去 Controller 上拉取 pinglist,如果 3 次拉取不到,那么就会删除本地已有 pinglist,停止 ping 动作。 在进行 ping 动作后,会将结果保存在内存中,当保存结果超过一定阈值或者到达了超时时间,就将结果上传到 Cosmos 中用于分析,如果上传失败,会有重试,超过重试次数则将数据丢弃,保证 Agent 的内存使用。
网络状况
根据论文中提到的,不同负载的数据中心的数据是有很大差异的,在 P99.9 时延时大概在 10-20ms,在 P99.99 延时大概在100+ms 。关于丢包率的计算,因为没有用 ICMP ping 的方式,所以这里是一种新的计算方式,(一次失败 + 二次失败)次数/(成功次数)= 丢包率。这里是每次 ping 的 timeout 是 3s,windows 重传机制等待时间是 3s,下一次 ping 的 timeout 时间是 3s,加一起也就是 9s。所以这里跟 Agent 最小探测周期 10s 是有关联的。二次失败的时间就是 (2 * RTT)+ RTO 时间。 Pingmesh 的判断依据有两个,如果超过就报警:
- 延时超过 5ms
- 丢包率超过
10^(-3)
在论文中还提到了其他的网络故障场景,交换机的静默丢包。有可能是 A 可以连通 B,但是不能连通 C。还有可能是 A 的 i 端口可以连通 B 的 j 端口,但是 A 的 m 端口不能连通 B 的 j 端口,这些都属于交换机的静默丢包的范畴。Pingmesh 通过统计这种数据,然后给交换机进行打分,当超过一定阈值时就会通过 Autopilot 来自动重启交换机,恢复交换机的能力。
Flashcat-Pingmesh 方案
业界方案大都实现了各自的ping-agent的能力,但对于controller生成pinglist的能力并未有好的开源方案。同时我们和一些客户交流,了解到目前数据中心架构与传统的leaf-tor-server架构不太一样,传统一个机顶交换机下server都在一个机柜下,现在数据中心一个交换机下机器可能在不同机柜,这种情况如果还是按交换机维度进行探测,当server机器探测故障后,无法快速定位到机器位置。因此,我们在开发之前就针对Tor以及机柜维度进行了设计。
Pimgesh应具备哪些能力?
- 具备最基础的Ping探测能力,即ICMP协议支持,同时也应支持TCP、UDP等协议的端口探测;
- 简化页面用户配置,用户只需配置数据中心名字、交换机CIDR值,数据中心支持的探测协议和端口等关键信息;
- 数据中心会有很多机柜、交换机和机器,如何避免ping风暴,因此需支持配置选取部分机柜、交换和机器进行探测,及探测比例配置,用户可灵活配置数据中心参与探测的交换机或机柜比例数,以及每个交换机或机柜下参与探测的Server比例数;
- 每个数据中心内部、默认所有机柜或交换机之间进行探测(Server比例数依旧生效)
- 每个数据中心之间,用户可配置默认规则,即两两数据中心之间,按照配置的协议进行探测。当然,用户也可自定义哪些数据中心之间按照所选协议进行探测,此时机柜或交换机以及Server比例数依旧生效;
- 探测结果进行有效聚合展示,多个数据中心有很多机柜或交换机以及机器,分三层结构展示探测结果,第一层展示所有数据中心之间的探测链路拓扑以及探测值、第二层展示数据中心内部每个机柜或交换机之间的探测拓扑和结果、第三层展示机柜或交换机下面所选Server之间的探测拓扑和结果;
- Ping故障一键停止探测的止损能力;
- 探测机器故障后,自动重新选替补机器能力;
- 数据中心配置变更后,能及时自动以新配置重新生成pinglist;
- 支持简便地配置报警规则;
- 探测结果写入支持prometheus协议的时序库中;
交换机和机柜模式配置差异
- 交换机模式,页面用户只需配置交换CIDR值即可,无需手动注册Server IP,我们会借助 Categraf 的心跳功能,自动判断出server ip应归属哪个交换机。
- 机柜模式,这种方式一般适用于客户环境中有自己的CMDB系统,可将其CMDB系统中的数据中心、机柜和机器关系通过OpenApi注册到Pingmesh系统中。
Pingmesh 架构设计:
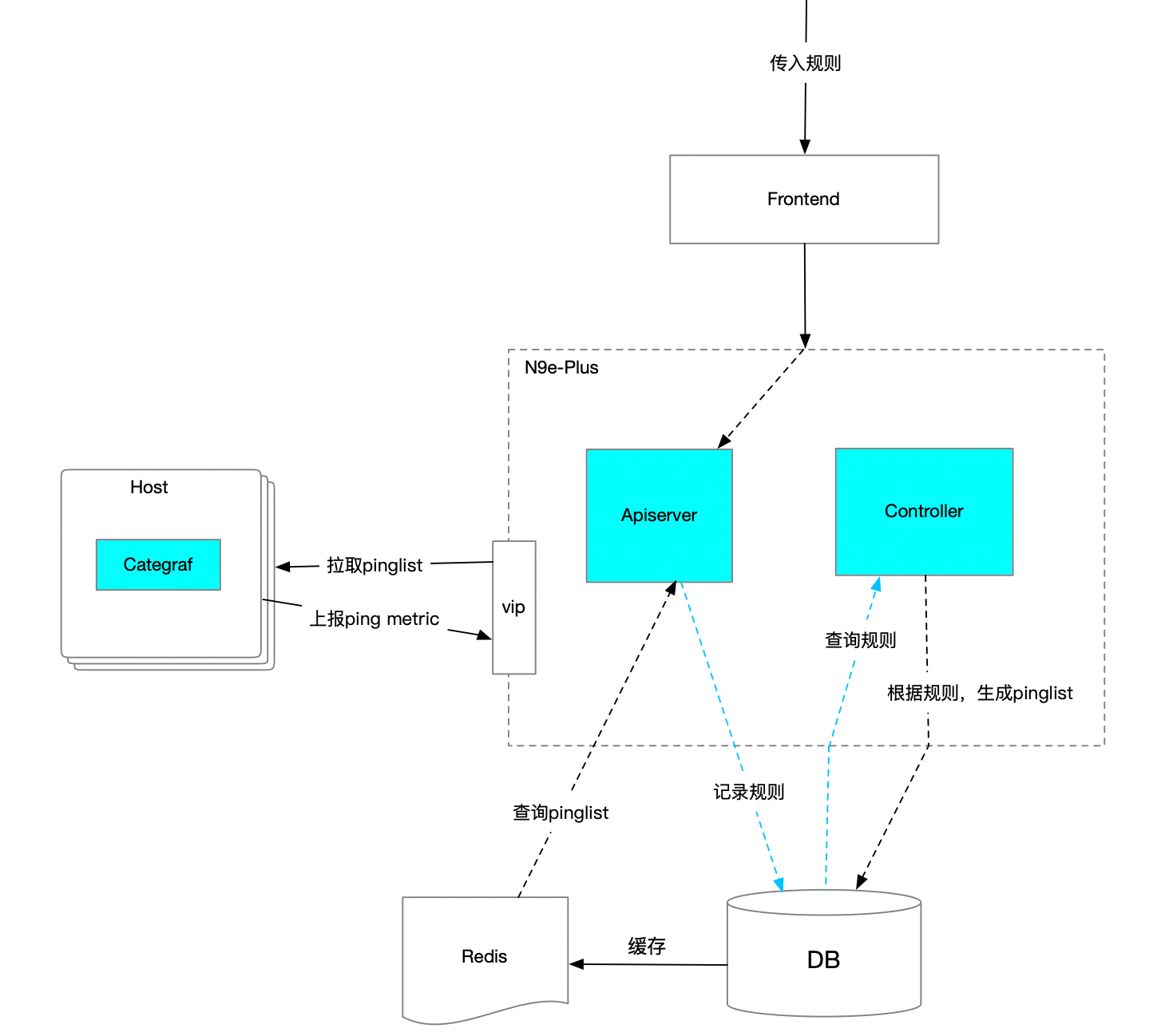
Apiserver
提供OpenApi:
- 用于注册、变更、查询数据中心原信息、探测规则(如:数据中心、探测协议、Tor交换机CIDR/机柜名、机器IP和机器名(机柜方式)、 探测百分比设置、数据中心之间探测规则设置 )。
- 数据中心三层结构拓扑图展示,以及历史探测曲线图、报警规则配置、一键降级等API。
- 提供给Categraf使用的查询pinglist接口。
Controller
生成pinglist的核心控制器逻辑,它需要定时从DB中查询最新的配置和规则,判断是否有发生变更,如果发生变更则重新执行pinglist生成逻辑。 从DB中查到配置后,判断是机柜模式还是交换机模式,因为这两种方式,其筛查Server IP的逻辑会有差异,之后需计算出每个数据中心,待探测的机柜或交换机是哪些,以及其下的Server Ip分别是多少,做好数据准备工作。接下来查看探测规则(数据中心内、数据中心之间),根据这些规则我们对每一台发起探测的Server 生成探测配置,并记录到DB中(因为我们底层真正执行探测任务的是Categraf Agent,需根据不同协议所使用的插件,生成不同的配置文件)。
此外,我们需新起一个协程,定时去对比新用户配置和已生成的pinglist是否一致,因为可能在我们生成新的pinglist后的一段时间内,用户变更或新增、删除了数据中心配置和规则,那需要将已生成的pinglist进行对比清理,避免用户配置变更后,依旧使用老的配置去探测,导致数据不准问题。
实现过程中还需要考虑另一个问题,数据中心有很多机器,但不是所有机器都装有categraf,或装有categraf但进程退出了等情况,如果我们只是单纯地按所有的机器数量去筛选一堆Server IP,那很有可能选出的机器都没有装agent,那也就无法进行探测和发现问题了,因此我们需要结合categraf自身的心跳上报的能力,来过滤出可用的Server IP。到了这里,我们可能会想到另一个问题,因为我们是按比例筛选机器的,而当某台机器down掉后,原本选了10台,现在只有9台可用机器了,这就会和用户配置的参与探测的服务器比例出现diff。出现这种情况,那我们就需要重新选一台可用机器补上去。当选择出来这批机器后,后面都需要一直用这些机器,除非遇到重新选的情况,这样可以保障我们指标量是固定的,同时也能满足探测的比例需求。
探测Agent
Pingmesh底层真正执行探测逻辑的是我们的Categraf,它是一个开源的项目,插件丰富、配置简单,这里就不做过多介绍了,大家可在github上搜索下即可。Categraf 会定时来中心端拉取本机的采集插件配置,当然,可能部署categraf的集群很多,这里中心端会将配置文件缓存到Redis中,降低对DB的查询压力,并提升接口查询效率。最终categraf会拿到最新的插件配置并进行探测,之后将探测结果上报给中心端,用于数据展示和报警配置使用。
额外说一点,如果存在边缘机房,那categraf可以将探测结果上报给边缘机房的 n9e-edge 模块,之后报警就可在这边缘机房内部闭环了,而且edge 会自动将指标转发给时序库,用于页面展示使用。
小结
Pingmesh 在复杂网络问题的排查中发挥了巨大的作用,本文分享了 Pingmesh 的实现思路,欢迎大家 联系我们试用。