线上服务器磁盘爆了,如何快速处理?
分享技术,用心生活
有一天突然收到预警短信,显示是服务器磁盘占用100% 心里一想这事大了,得赶紧处理啊!深一吸口气默念:问题不大,小事小事~
不过,线上遇到这情况,还是挺令人头大的!

先来看问题,登录上到监控台,2台报警了!
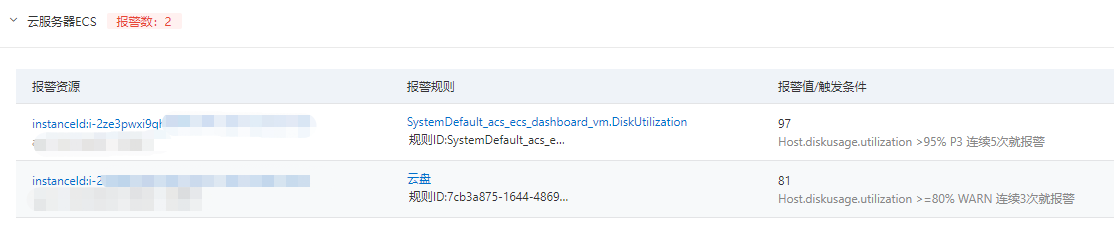
再看服务状况
(如果是线上,那么顺序一定是先解决掉磁盘占用问题,而不是先看服务。这里为了阅读方便,先把服务情况展现出来)

看到这,头更大了,写入数据失败!心里凉了半截,已经很严重影响业务了...
1. 查找占用空间大的文件
首先应该思考,先检查一下是哪里占用磁盘比较多,然后再视情况处理
登录服务器后,在根目录执行命令,目的是查找占用空间大的目录
du -h --max-depth=1
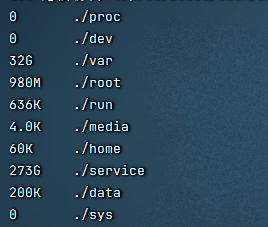
发现在service下占用273G,大概已经想到了是某个服务的占用问题。继续查找;
cd service进入到service目录;再次执行上面的命令,多次查找后(步骤省略...)
发现是nacos服务的占用问题
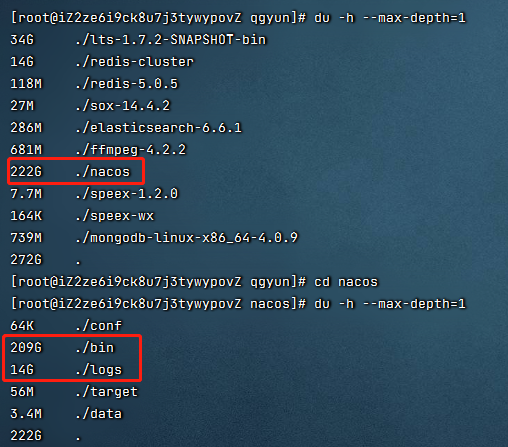
原来是nacos的log和bin目录下的log占用过大。那么就可以先从这里下手,直接把部分日志干掉!
进入到nacos/bin/logs目录
du -ah *
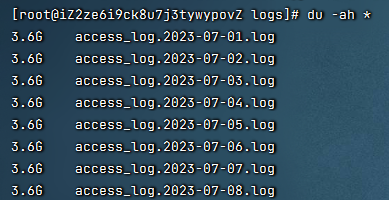
可以看到每个日志文件都占用了3.6G,确实影响很大!
2. 删除大文件
那么,就需要执行很多程序员闻之失色的命令了,rm
最好是把这个工作交给运维或者技术领导来做,不然删错或删多了那就更麻烦了。
最好是按日志的日期目录来删,每次删的时候指定日期目录。慢一点删严谨一点不会出错。
处理后,我们再来看下占用情况
df -h
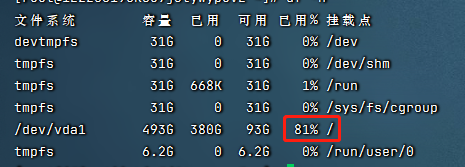
磁盘占用下降到81%了,终归是暂时解决了。
总结:遇到线上问题,我们首先需要解决问题,不要管是不是彻底解决还是临时解决,先保证服务可用性。像这种场景,只是临时处理。根源还是在于nacos的日志没有及时处理或者说是日志配置不合理。临时解决后,那么就要去改这一块,比如可以通过脚本去定时删除较久远的日志,也可以通过配置日志级别减少日志写入的大小。此处不再详细展开。